
From zero-shot classification to pairwise LLM ranking
tldr; LLMs can struggle with some zero-shot classification tasks. Instead of direct classification, we can let LLM compare the inputs, then infer the ranking weights and use that to predict the classification labels.
Zero-shot classification by LLMs sucks
LLMs really struggle with a whole range of tasks for zero-shot classification. I observed personally two types of behaviour:
- LLM guardrails will prevent it from directly classifying input data
- it is really biased towards one label.
Multilabel classification tasks are usually even worse in this regard. I tried to overcome this problem in past by the divide and conquer approach. Splitting the task into several smaller ones can help LLM to increase the overall accuracy. We could generate several simpler features with structured output and then use those features with standardised ML methods to predict the classification label. This approach is also valid, but that is for another blog in future. Moreover, this has one inherent flaw. You have to be creative enough to come up with those questions so that LLM can create the corresponding features.
Then it struck me. Can I let LLM choose which data input is more likely to be a member of the target class label? Maybe this is too abstract, so let’s use the following example. Imagine we want to prepare a dataset of news titles and classify them as sarcastic or non-sarcastic. We will consider the first 200 rows of this dataset as a toy example for this article. In this dataset, we already have is_sarcastic key with ground truth, which will be useful later for evaluation.
ollama/gemma3:4b> Analyze this headline for sarcasm. Respond with JSON containingis_sarcastic (bool), confidence (Low/Medium/High), and explanation (str).thirtysomething scientists unveil doomsday clock of hair loss{ "is_sarcastic": true, "confidence": "High", "explanation": "The phrase \"doomsday clock of hair loss\" is a hyperbolic and dramatic way to describe a common and often distressing experience. The juxtaposition of \"thirtysomething scientists\" with a catastrophic image like a \"doomsday clock\" strongly suggests sarcasm. It's likely intended to be humorous by exaggerating the concern about hair loss."}Excellent, right? Problem solved, and we can go home. After I ran this for the top 200 titles, according to gemma3:4b all of them are sarcastic and the LLM will provide AI sloppy explanation to every single one. I tried to play around with the prompt, but that didn’t help.
Just use bigger LLM.
Well, that can be a) costly and b) sometimes the safeguards will screw up with the answer, and you will get a biased answer.
Then it occurred to me. If I can’t force LLM to classify it directly, can I force it to pick one of the two given inputs? With enough comparisons, we should be able to rank the input data and hence be able to classify them! This is a more difficult task, and moreover, during classification, we don’t care about the ordering within a given class. So, in other words, the effort spent to order titles by how sarcastic they are within the class is useless. However, it seems that additional effort is required in order to squeeze some extra predictive power from LLMs.
Comparison
Let’s ask LLM to pick up the more sarcastic title.
ollama/gemma3:4b> Compare these two headlines for sarcasm. Respond with JSON containingmore_sarcastic (text_1/text_2), confidence (Low/Medium/High), and explanation (str).text_1: report: bridge probably has whole mess of bats under theretext_2: friday talking points -- prelude to silly season{ "more_sarcastic": "text_2", "confidence": "High", "explanation": "Headline 'friday talking points -- prelude to silly season' strongly suggests sarcasm. 'Silly season' is a well-established term for the period leading up to the holiday season, often associated with political manoeuvring and exaggerated claims. The phrasing is intentionally dismissive and suggests the talking points are unimportant or even ridiculous. 'report: bridge probably has whole mess of bats under there' could be sarcastic, but it's far more straightforward and potentially genuine."}Well, that didn’t work out as expected. LLM seems to be wrong also on this one. However, there is still hope. Perhaps when we collect a sufficient amount of those comparisons, we could still infer an approximate ranking for the titles. The question is, what should we compare with what?
Graphs for comparisons
You can skip this part if you are interested only in results.
The naive solution would be to do random comparisons. However, this approach is naive for a very simple reason. Ranking is completely relative based on the data we used for comparison. With randomly generating pairs, we have no guarantee that we will have one connected graph and hence that we ranking is done on the basis of the whole dataset.
Complete graph
The next intuitive solution is to use a complete graph. However, that becomes very expensive in terms of the number of comparisons very quickly.
The number of edges will grow with , where is the number of nodes.
Higher ranking complete graphs
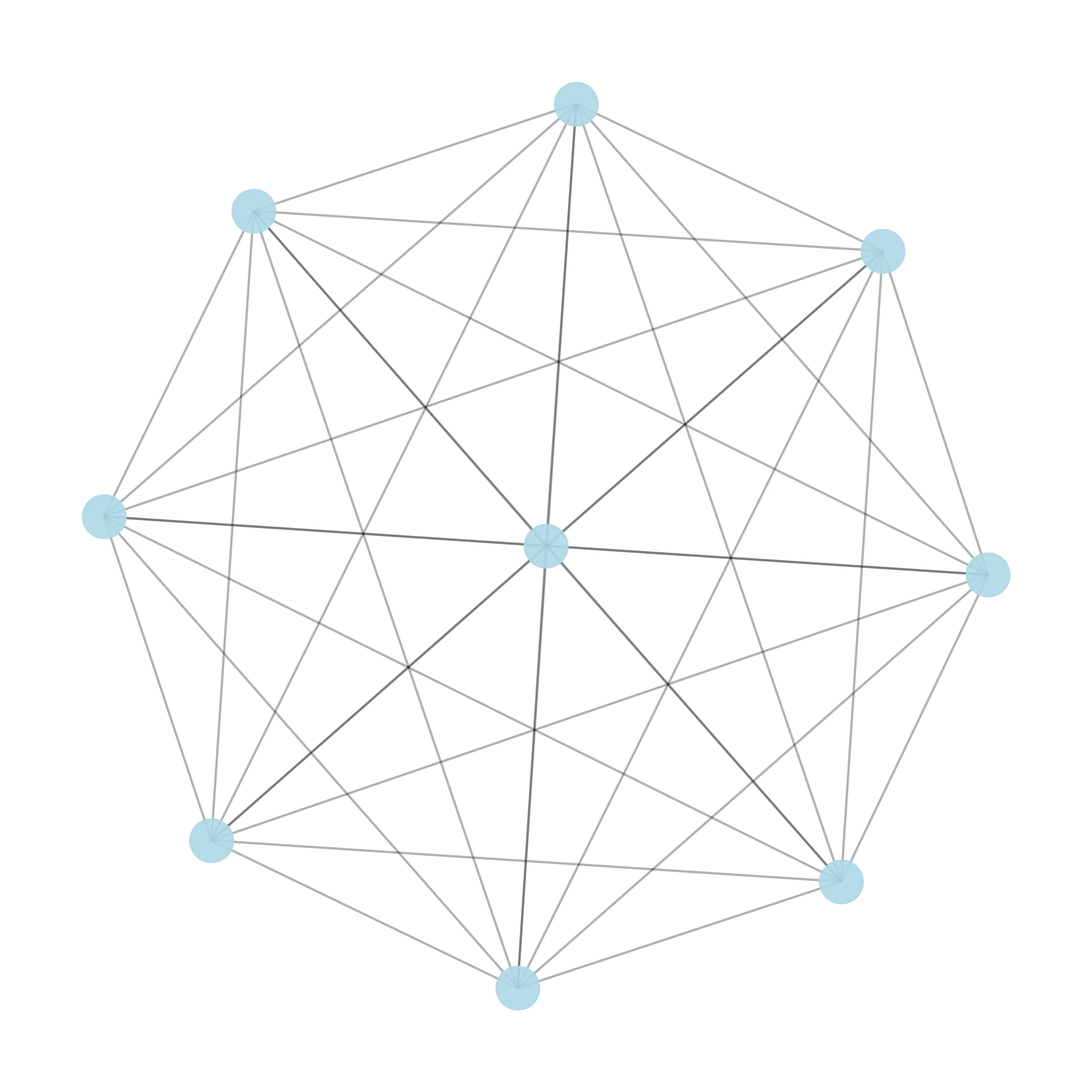
What about splitting the data into several complete graphs and then connecting them together? We will get complete graphs on steroids. I thought about this a lot, and splitting into a constant number of complete graphs is not ideal, as the number of nodes will grow. I introduce to you the following idea. Assuming we have nodes, we can split them into groups of nodes. For every group, we will create a complete graph, and then we will also create a complete graph for every -th node from the subgraphs. Here is a visualisation of the complete graph () vs. the complete graph with rank two.
 The number of edges will grow with , so considerably better.
The number of edges will grow with , so considerably better.
Can we generalise this idea? Yes! The case of the complete graph is actually rank one, and the second example with subgraphs is the case with rank two. So, what does rank three look like? I tried to visualise it in 2D, but it is too complex to make any sense of it. I came up with an alternative way to visualise it. We don’t need to draw all the edges in a complete graph as we know that all nodes are connected to each other. Maybe it is sufficient to just connect them and assume that all other edges are there implicitly. Here is the rank two case in this new representation.
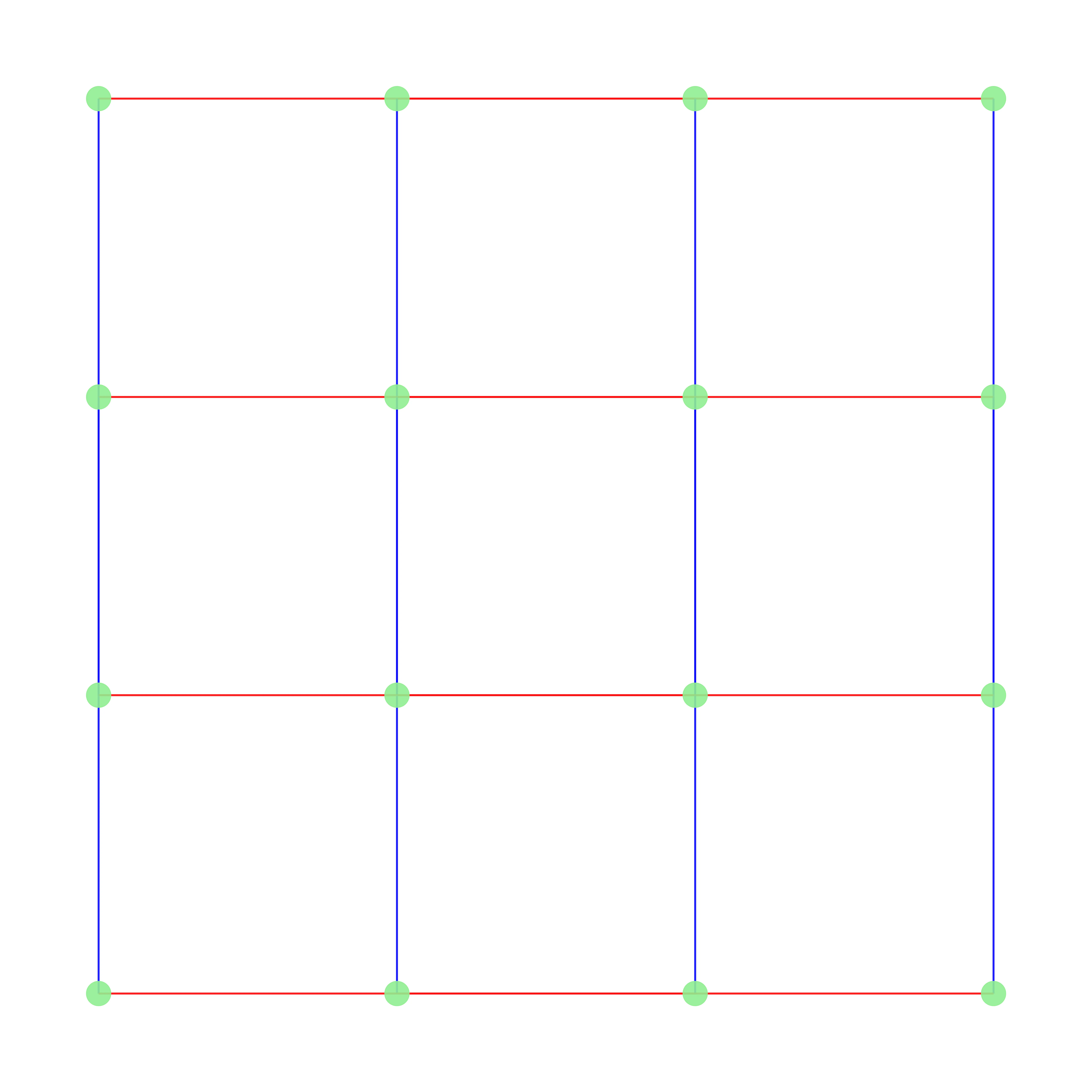 The red coloured lines connect the subgraphs in one dimension, creating smaller complete graphs, and then the -th nodes of those graphs are connected between each other with blue lines in a different dimension, creating complete graphs in different dimensions. Now it is trivial to visualise the rank 3 case.
The red coloured lines connect the subgraphs in one dimension, creating smaller complete graphs, and then the -th nodes of those graphs are connected between each other with blue lines in a different dimension, creating complete graphs in different dimensions. Now it is trivial to visualise the rank 3 case.
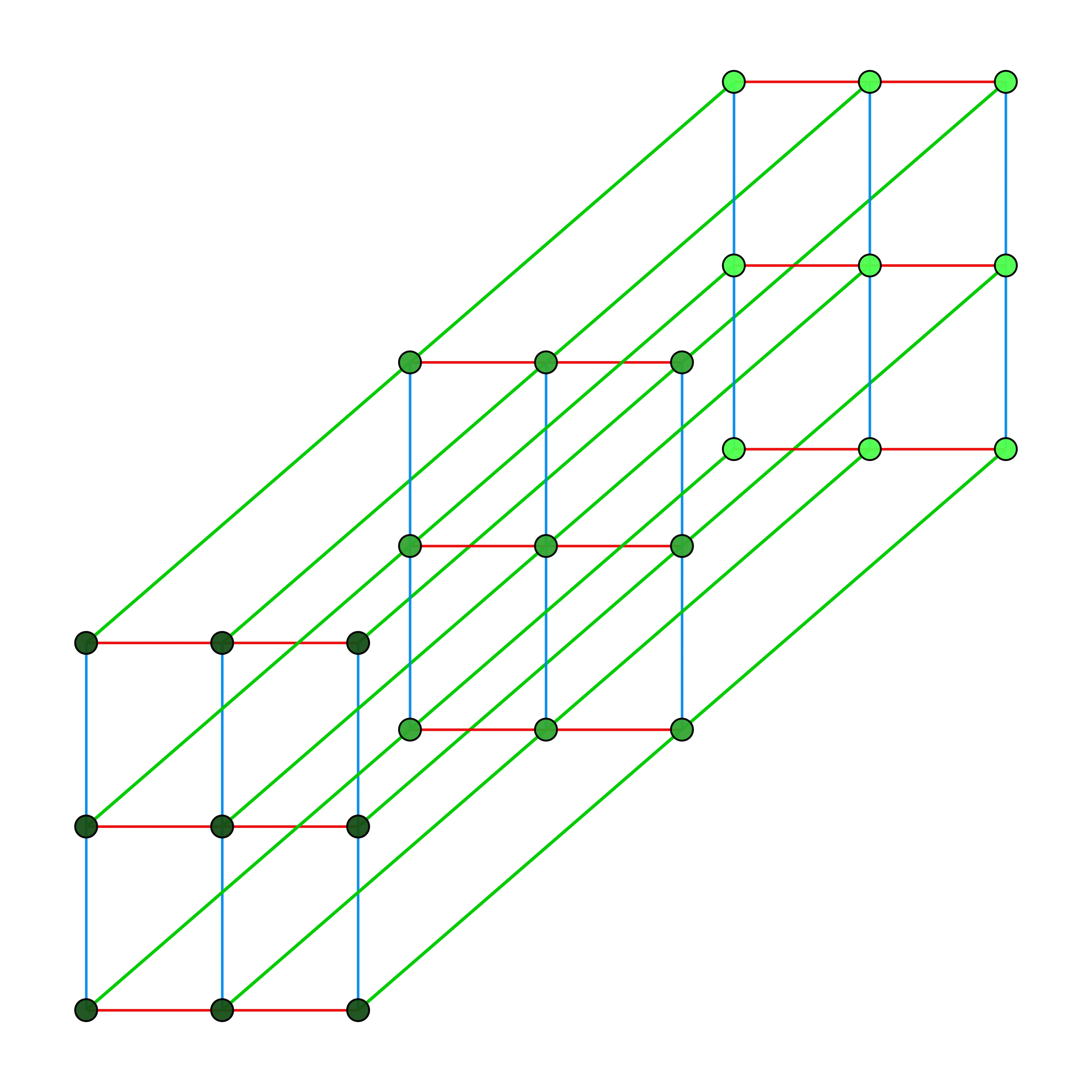 The number of edges will grow with , another improvement.
The number of edges will grow with , another improvement.
What about the general case? Maybe you’ve guessed it correctly at this point. The number of edges will grow with and that will asymptotically go to .
The highest rank can be achieved for powers of 2 (). I didn’t find any name for those graphs. We can also prove that with a higher rank, we will have fewer edges in the graph. You can try to prove that inequality yourself or see the solution here.
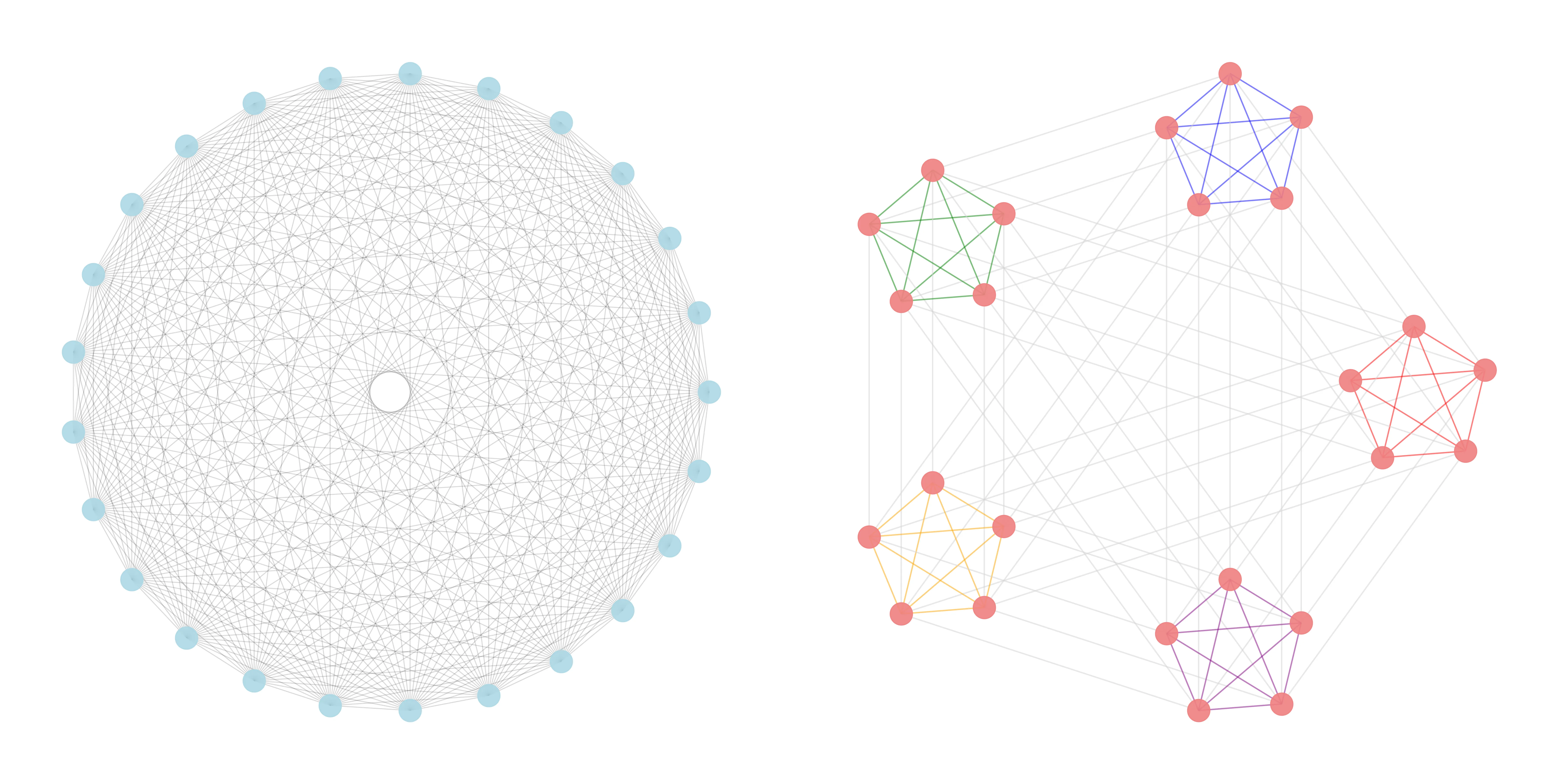
Circulant graphs
The other type of graphs that are well-known are circulant graphs. Here is graph with eight nodes and offsets=.
 Here is another circulant graph with thirteen nodes and offsets=.
Here is another circulant graph with thirteen nodes and offsets=.
 The good news here is that the number of edges in those graphs is roughly the number of nodes times the number of offsets. I say roughly because for and offsets= we will have only two edges. However, for and , this holds.
The good news here is that the number of edges in those graphs is roughly the number of nodes times the number of offsets. I say roughly because for and offsets= we will have only two edges. However, for and , this holds.
Higher ranking circulant graphs
We can do exactly the same step and generalise the same way we did with complete graphs. Rank two is already a bit difficult to visualise. I will not provide the whole graph in 2D, but here is the image of a toroid. That would be similar to a circulant graph with rank two and offsets=. With more offsets, we would see new edges in the direction of the rings.
 Alternatively, we can use the same simplified visualisation; however, we can’t see the offsets in it, so in a way it is much cruder. The connected lines in one direction and one colour represent one circulant graph with given offsets.
Alternatively, we can use the same simplified visualisation; however, we can’t see the offsets in it, so in a way it is much cruder. The connected lines in one direction and one colour represent one circulant graph with given offsets.
Ranking weights
Sweet, now we have the comparisons. What is left to do is to try to infer the ranking weights. This problem can be mapped onto the problem. If we let multiple teams/players compete against each other, we would like to get their ELO/ranking that would help us to predict the future match between two players that didn’t play yet. The simplest approach is to use Bradley–Terry model, which models the probability of being chosen over as
where and are the ranking weights.
The second approach I will explore in this article is using TrueSkill model developed by Microsoft. The math behind it, and here is the paper from NIPS.
Results
The direct prediction is the baseline, which is not too difficult to beat.
Accuracy: 0.4350Precision: 0.4322Recall: 1.0000F1 Score: 0.6035ROC AUC: 0.5044
Confusion Matrix: Predicted Neg Pos Neg | 1 | 113 |Actual Pos | 0 | 86 |Complete rank one means that we have a complete graph, that is the most tie consuming to compute. Circulant rank 1 means that we have simple circulant graph.
| Graph Type | Bradley-Terry AP (gemma3:4b) | Bradley-Terry AUC (gemma3:4b) | TrueSkill AP (gemma3:4b) | TrueSkill AUC (gemma3:4b) |
|---|---|---|---|---|
| Complete-Rank1 | 0.4975 | 0.5835 | 0.5071 | 0.5760 |
| Complete-Rank2 | 0.4017 | 0.4417 | 0.4831 | 0.5419 |
| Complete-Rank3 | 0.5038 | 0.5577 | 0.5098 | 0.5540 |
| Complete-Rank4 | 0.3851 | 0.4221 | 0.5112 | 0.5640 |
| Circulant(1)-Rank1 | 0.3675 | 0.3739 | 0.5400 | 0.6150 |
| Circulant(1_2)-Rank1 | 0.3430 | 0.3329 | 0.6279 | 0.6581 |
| Circulant(1_2)-Rank2 | 0.6157 | 0.6821 | 0.6199 | 0.6806 |
| Circulant(1_2)-Rank3 | N/A | N/A | 0.6073 | 0.6865 |
| Circulant(1_2_3)-Rank1 | 0.3483 | 0.3313 | 0.5917 | 0.6715 |
| Circulant(1_2_3_5)-Rank1 | 0.3447 | 0.3317 | 0.5963 | 0.6660 |
| Circulant(1_2_3_5_7)-Rank1 | 0.3512 | 0.3277 | 0.6300 | 0.6699 |
| Circulant(1_2_3_5_7_11)-Rank1 | 0.3473 | 0.3304 | 0.6306 | 0.6662 |
| Circulant(1_2_4)-Rank1 | 0.3309 | 0.3074 | 0.6537 | 0.7004 |
| Circulant(1_2_4)-Rank2 | 0.6382 | 0.6886 | 0.6487 | 0.6892 |
| Circulant(1_2_4)-Rank3 | 0.3324 | 0.3317 | 0.5941 | 0.6758 |
| Circulant(1_2_4_8)-Rank1 | 0.6264 | 0.6897 | 0.6539 | 0.7011 |
| Circulant(1_2_4_8)-Rank2 | 0.6372 | 0.6859 | 0.6547 | 0.6922 |
| Circulant(1_2_4_8)-Rank3 | 0.3376 | 0.3301 | 0.5958 | 0.6785 |
| Circulant(1_2_4_8_16)-Rank1 | 0.3409 | 0.3434 | 0.6469 | 0.6820 |
Definitely Circulant(1_2_4)-Rank1 and Circulant(1_2_4_8)-Rank1 are the top candidates. Also, considering we need roughly six times more tokens in case of Circulant(1_2_4)-Rank1 in comparison to the direct ranking, and we get an additional AUC, I think it is a great success.
Let’s try to use a more recent model. I selected gpt-5-nano as the most recent and cheapest model from OpenAI.
Accuracy: 0.6950Precision: 0.7273Recall: 0.4651F1 Score: 0.5674ROC AUC: 0.6668
Confusion Matrix (Visual): Predicted Neg Pos Neg | 99 | 15 |Actual Pos | 46 | 40 |Definitely noticeable improvement, but yet far from perfect.
| Graph Type | # Comparisons | gemma3:4b BT | gemma3:4b TrueSkill | gpt-5-nano BT | gpt-5-nano TrueSkill |
|---|---|---|---|---|---|
| complete-rank1 | 19,900 | 0.5835 | 0.5760 | 0.2701 | 0.7237 |
| complete-rank2 | 2,610 | 0.4417 | 0.5419 | 0.2647 | 0.7339 |
| complete-rank3 | 1,430 | 0.5577 | 0.5540 | 0.6986 | 0.6966 |
| circulant(1)-rank1 | 200 | 0.3739 | 0.6150 | 0.6623 | 0.6642 |
| circulant(1,2)-rank1 | 400 | 0.3329 | 0.6581 | 0.7037 | 0.6942 |
| circulant(1,2)-rank2 | 800 | 0.6821 | 0.6806 | 0.2720 | 0.7329 |
| circulant(1,2)-rank3 | 1,181 | N/A | 0.6865 | 0.7290 | 0.7365 |
| circulant(1,2,4)-rank1 | 600 | 0.3074 | 0.7004 | 0.7329 | 0.7265 |
| circulant(1,2,4)-rank2 | 1,195 | 0.6886 | 0.6892 | 0.7402 | 0.7462 |
| circulant(1,2,4)-rank3 | 1,181 | 0.3317 | 0.6758 | 0.7038 | 0.7037 |
| circulant(1,2,4,8)-rank1 | 800 | 0.6897 | 0.7011 | 0.7280 | 0.7295 |
| circulant(1,2,4,8)-rank2 | 1,590 | 0.6859 | 0.6922 | 0.7487 | 0.7487 |
| circulant(1,2,4,8)-rank3 | 1,181 | 0.3301 | 0.6785 | 0.2825 | 0.7161 |
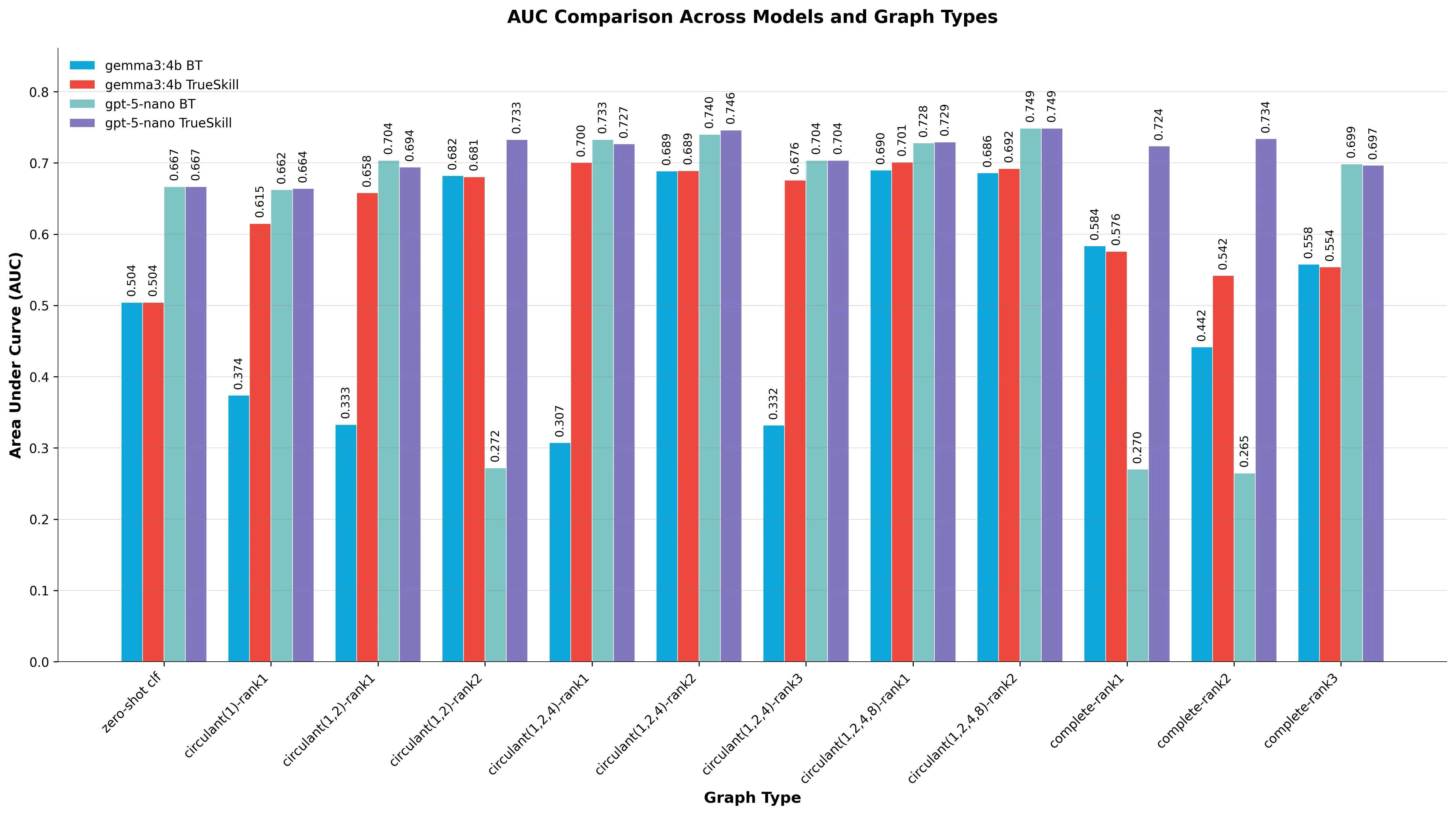
What if we used gpt-5 instead of gpt-5-nano? Well, that model is way better in terms of performance.
Accuracy: 0.8950Precision: 0.9452Recall: 0.8023F1 Score: 0.8679ROC AUC: 0.8836
Confusion Matrix (Visual): Predicted Neg Pos Neg | 110 | 4 |Actual Pos | 17 | 69 || Graph Type | # Comparisons | gemma3:4b TrueSkill | gpt-5-nano TrueSkill | gpt-5 TrueSkill |
|---|---|---|---|---|
| circulant(1)-rank1 | 200 | 0.6150 | 0.6642 | 0.8436 |
| circulant(1,2)-rank1 | 400 | 0.6581 | 0.6942 | 0.8943 |
| circulant(1,2)-rank2 | 800 | 0.6806 | 0.7329 | 0.9559 |
| circulant(1,2,4)-rank1 | 600 | 0.7004 | 0.7265 | 0.9238 |
| circulant(1,2,4)-rank2 | 1,195 | 0.6892 | 0.7462 | 0.9493 |
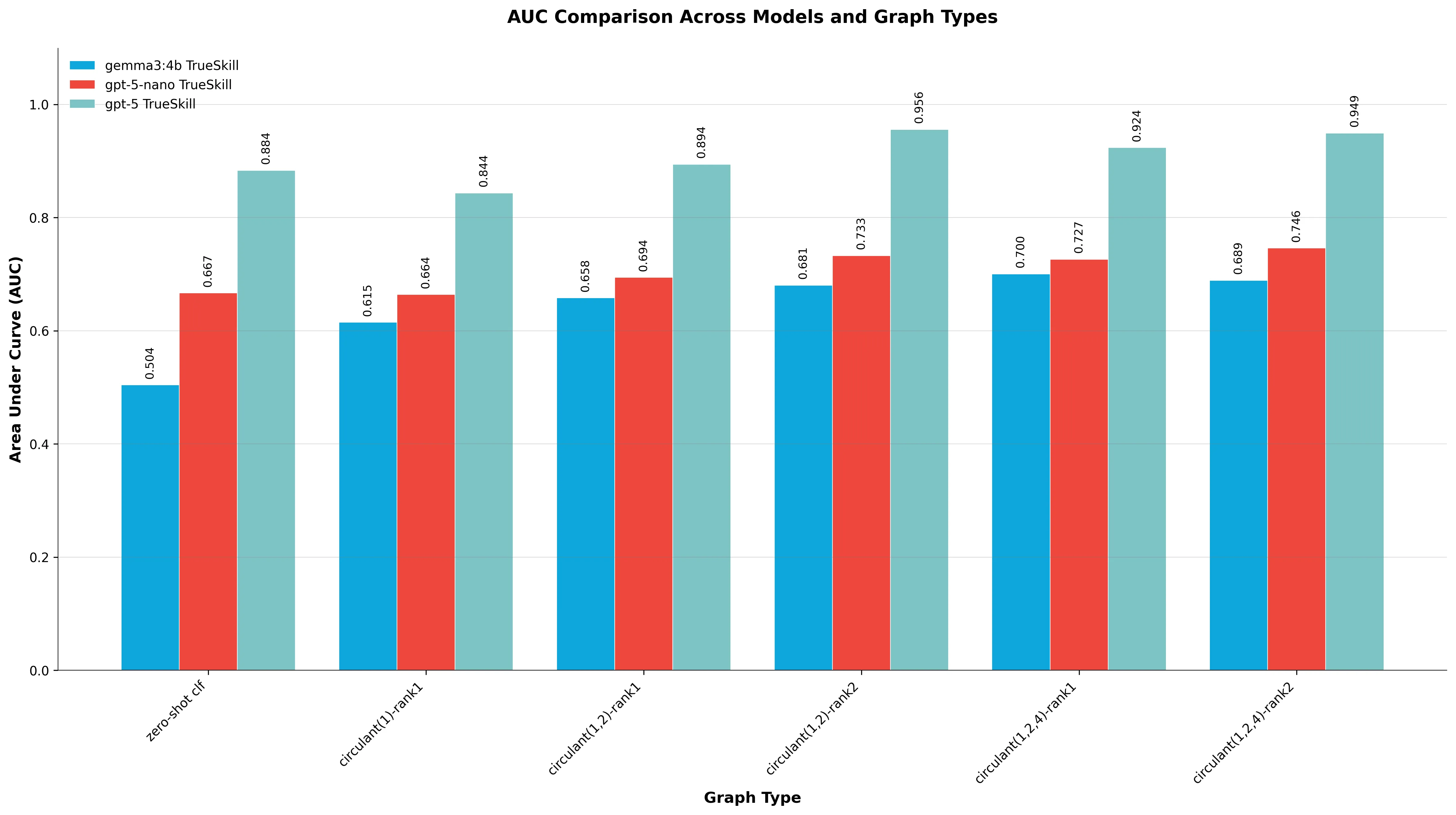
Key findings
From results, it is clear that pairwise ranking can improve the prediction in terms of AUC.
-
Small models benefit most: The increase in
gemma3:4Bis AUC () between the zero-shot classification baseline and ranking with graphcirculant(1,2,4)-rank1. Whereas ingpt-5, the improvement using graphcirculant(1,2)-rank2is AUC (). -
Larger models still improve: Even
gpt-5, which already achieved AUC with direct zero-shot classification, reached AUC withCirculant(1,2)-Rank2- an additional boost. -
Graph structure matters: My initial intuition that complete graphs with rank will be the best has proven to be wrong. Circulant graphs with powers-of-2 offsets consistently outperformed other structures, likely due to their balanced connectivity patterns.
-
TrueSkill vs Bradley-Terry: When the frequency of connection increases, I suspect the noise from LLM actually decreases the accuracy of weights in the case of BT. TrueSkill seems to be resistant to this issue to some degree. Trueskill seems to be a better choice when the comparisons are noisy.
Conclusion
When LLMs fail at direct zero-shot classification due to bias or guardrails, pairwise ranking offers a robust alternative. By framing the problem as “which is more <target-label>?” instead of “is this <target-label>?”, we can extract reliable signals even from smaller, cheaper models.